The Model Settings
The Model Settings tab allows you to tune the model generation to your individual needs. You can specify what parameters you want to predict, the required precision and how fast your model needs to be. For example, if the size of your objects is known, you can tell ONE AI to only predict object positions to save resources. To achieve the best results, you also need to make some estimates about your task, like specifying the expected size of objects or the overall complexity of the task.
We have a guide on choosing the right parameters, which explains the settings using different example tasks. If you're unsure whether your settings are correct, this is a great place to learn more.
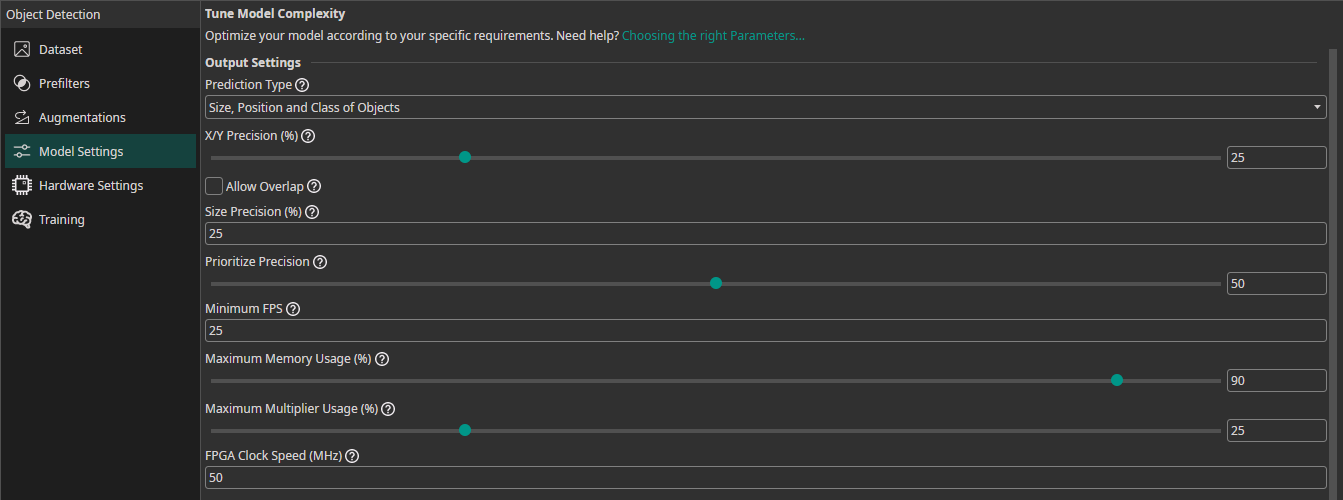
Output Settings
In the Output Settings, you can control the output of your model and specify the amount of hardware resources it is allowed to use.
For Classification Tasks
Classification Type: The classification type determines how your model assigns classes to images:All Individual Classes: A single image can have multiple classes present, e.g. an image that shows a dog and a cat but no bird has the label (1, 1, 0).One Class per Image: A single image can only have one present class, e.g. only one of the classes no object, defective, valid can be true.At Least One Class? (Y/N): You have a dataset with different classes but are only interested in whether at least one class is present, e.g. you want to know if your product has a defect but it doesn't matter which defect.Regression(advanced): Label names are interpreted as continuous values (e.g. 0 L, 0.5 L, 1 L, 1.5 L, 2 L). Assign one label per image and the model predicts continuous values. When exporting as ONNX with pre/postprocessing, the output is mapped to the closest label name. Exporting without pre/postprocessing or using TFLite / VHDL returns the exact predicted value.
For Object Detection Tasks
Prediction Type: The prediction type determines what parameters your model needs to predict. If you need to predict fewer parameters, ONE AI is able to generate a simpler model that requires fewer computations. Some of the options convert the object detection task to a classification task. This allows you to use a dataset that is already annotated with object bounding boxes for training a classification model. ONE AI converts the labels after applying data augmentation, which is more precise than converting the dataset in the beginning, e.g. if one of the objects is moved out of frame.Size, Position and Class of Objects: The model predicts the size, position and class for each detected object.Position and Class of Objects: The model only predicts the position and class of detected objects. This setting is useful when you already know the size of the objects, e.g. the images show a conveyor belt and the objects always have the same size.All Present Object-Classes(converts to classification): The model predicts which objects are present in the image but provides no further information on their size or location. For example, this option can be used for quality control to detect the presence of different types of defects.Class with Largest Combined Object Area(converts to classification): The model predicts the object class that occupies the largest combined area within the image.Class with Most Objects(converts to classification): The model predicts the object class that appears in the image the most.At Least One Object? (Y/N)(converts to classification): The model predicts whether at least one object is present in the image or not.
Position Prediction Resolution (%): Sets the resolution level for predicting x and y coordinates. At 100%, positions are predicted with pixel-level accuracy. Lower values (e.g. 10%) reduce the resolution grid (e.g. 64×48 instead of 640×480), which increases speed and can help the model generalize better.Allow Overlap: Controls how objects that fall within the same grid cell are handled. When enabled, objects in the same cell are merged. When disabled, ONE AI automatically refines the grid to avoid overlap and detect each object separately.Size Prediction Effort (%): Controls the computational effort for predicting object sizes. At 100%, the model uses more neurons for accurate size predictions. At 25%, complexity is reduced for faster predictions, which is sufficient for most applications.Precision Recall Prioritization: Adjusts the model's balance between false positives and false negatives. Values below 50% focus on reducing false positives (fewer incorrect detections). Values above 50% focus on reducing false negatives (fewer missed detections). Set to 50% for a balanced approach.Optimize Small Objects: Enables additional optimization to improve detection quality for small objects in images.
For Segmentation Tasks
Segmentation Type: Defines the output format for segmentation models:One Class per Pixel: The model outputs a segmentation matrix with the corresponding class for each pixel.Size, Position and Class of Objects: The model outputs detailed predictions including object size, exact position, and class for each detected object.Position and Class of Objects: The model predicts the location and class of each object without specific size information.All Present Object-Classes(converts to classification): The model identifies all classes of objects present in the image without positional or size details.Class with Largest Combined Object Area(converts to classification): The model predicts the object class that occupies the largest combined area within the image.Class with Most Objects(converts to classification): The model predicts the object class appearing most frequently within the image.At Least One Object? (Y/N)(converts to classification): The model provides a binary prediction indicating whether at least one object is present.
Position Prediction Resolution (%): Same as for object detection — controls the grid resolution for position predictions.Segmentation Resize Threshold (%): When resizing the segmentation mask, the area of the segmented object below a pixel is calculated. This threshold controls what percentage of area is sufficient to mark a pixel as belonging to an object.Precision Recall Prioritization: Same as for object detection — adjusts the balance between false positives and false negatives.
Hardware Usage Settings
Minimum FPS: The minimum number of images the model needs to process per second with hardware selected in theHardware Settingstab.Maximum Memory Usage (%): You can limit the amount of memory that the predicted model will use.Maximum Multiplier Usage (%): You can also limit the amount of DSP elements that the predicted model can use. If you aren't using an FPGA this setting is ignored.FPGA Clock Speed (MHz): If you are using an FPGA, you need to provide its clock speed. Otherwise, this setting is ignored.
Input Settings
To achieve the best results, you need to provide some additional information about your task. ONE AI will use this information to tailor the generated model to your individual use case.
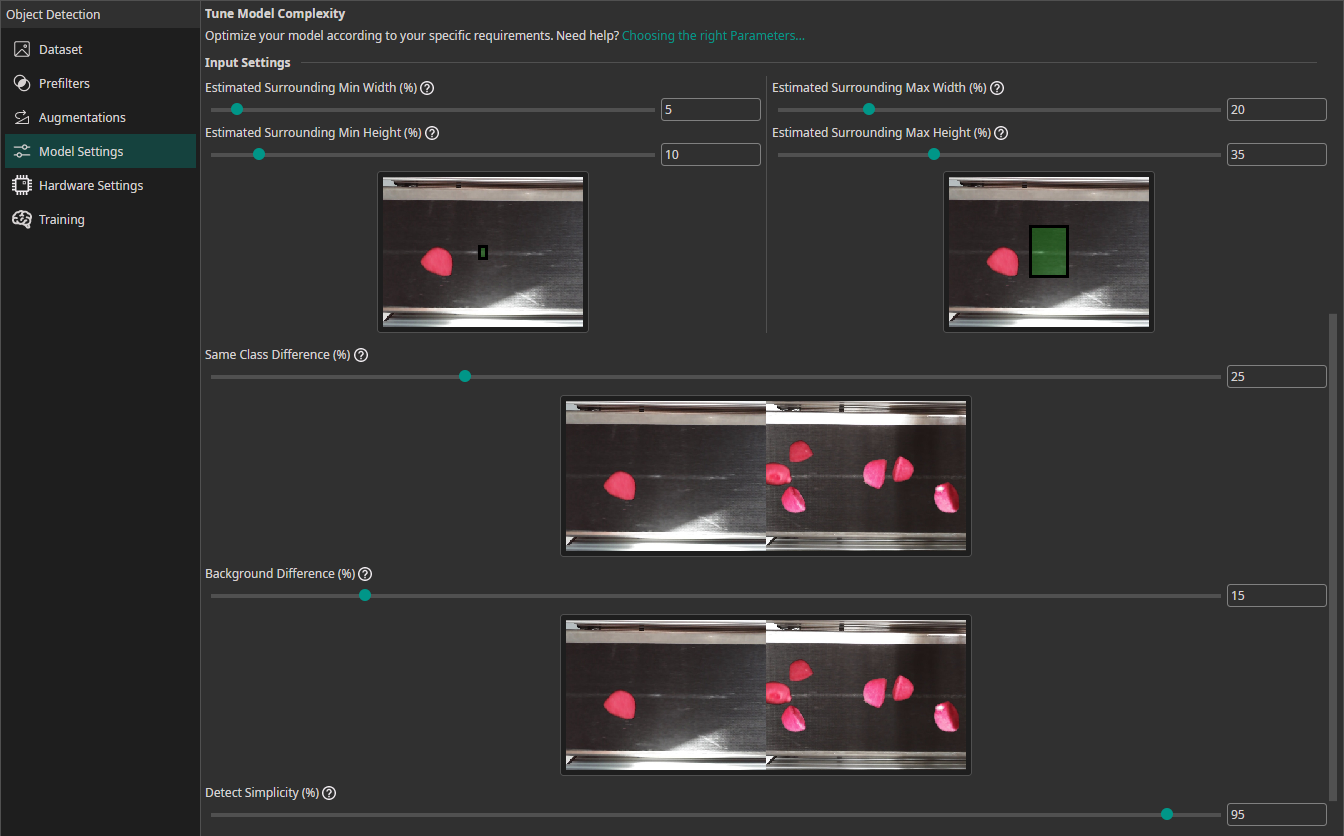
Surrounding Size Mode(advanced): Choose how to estimate the surrounding area needed for accurate detection:Relative To Object: The surrounding area is calculated based on the size of the object itself. Useful when objects are well-separated.Relative To Image: The surrounding area is determined as a percentage of the entire image. Useful when objects are close together or context is important.
Estimated Surrounding Min Size (%)(when Relative To Object): Estimate the minimum surrounding area relative to the object size required to detect the smallest object correctly.Estimated Surrounding Max Size (%)(when Relative To Object): Estimate the maximum surrounding area relative to the object size required to detect the largest object correctly.Estimated Surrounding Min Width (%)(when Relative To Image): Estimate the minimum width of the area required to detect the smallest object correctly.Estimated Surrounding Min Height (%)(when Relative To Image): Estimate the minimum height of the area required to detect the smallest objects.Estimated Surrounding Max Width (%)(when Relative To Image): Estimate the width of the area required to detect the largest objects.Estimated Surrounding Max Height (%)(when Relative To Image): Estimate the height of the area required to detect the largest objects.Same Class Difference (%): Estimate how much objects within the same class can vary. 10% means minimal variation (e.g. the same label under different lighting), 85% means significant variation (e.g. different label shapes and prints).Background Difference (%): Estimate how much the background varies after applying prefilters. 0% for uniform backgrounds, 15% for slight variation (same conveyor belt), 100% for entirely different locations.Detect Complexity (%): Estimate how easy it is to detect the object class. 5% for simple tasks (black circles on white background), 60% for moderate tasks (scratches on a surface), 95% for complex tasks (differentiating cat breeds).
Note that these parameters apply to the preprocessed and augmented images. If you use size augmentations, for example, make sure the estimated surrounding values still match the resulting range of image sizes.
Check out our guide on choosing the right parameters.
Basic Mode
In Basic Mode, the input settings are simplified into four high-level questions that automatically configure the advanced parameters:
Size of Objects or Features: Select the size categories applicable to your dataset (Tiny, Small, Medium, Big). Multiple categories can be selected to define the range. This automatically sets the object width/height estimates.Number of Objects or Features: Specify the feature count (Always one object, A few features, Many features). This controls the maximum and average number of features for classification.Type of Environment: Describe the environment (Controlled, Limited, Natural). This automatically sets Background Difference and Detect Complexity.Type of Objects or Features: Describe the variability (Similar, Limited, Open). This sets Same Class Difference and Detect Complexity.
For Classification Tasks
If you are training a classification model, you need to provide some additional information:
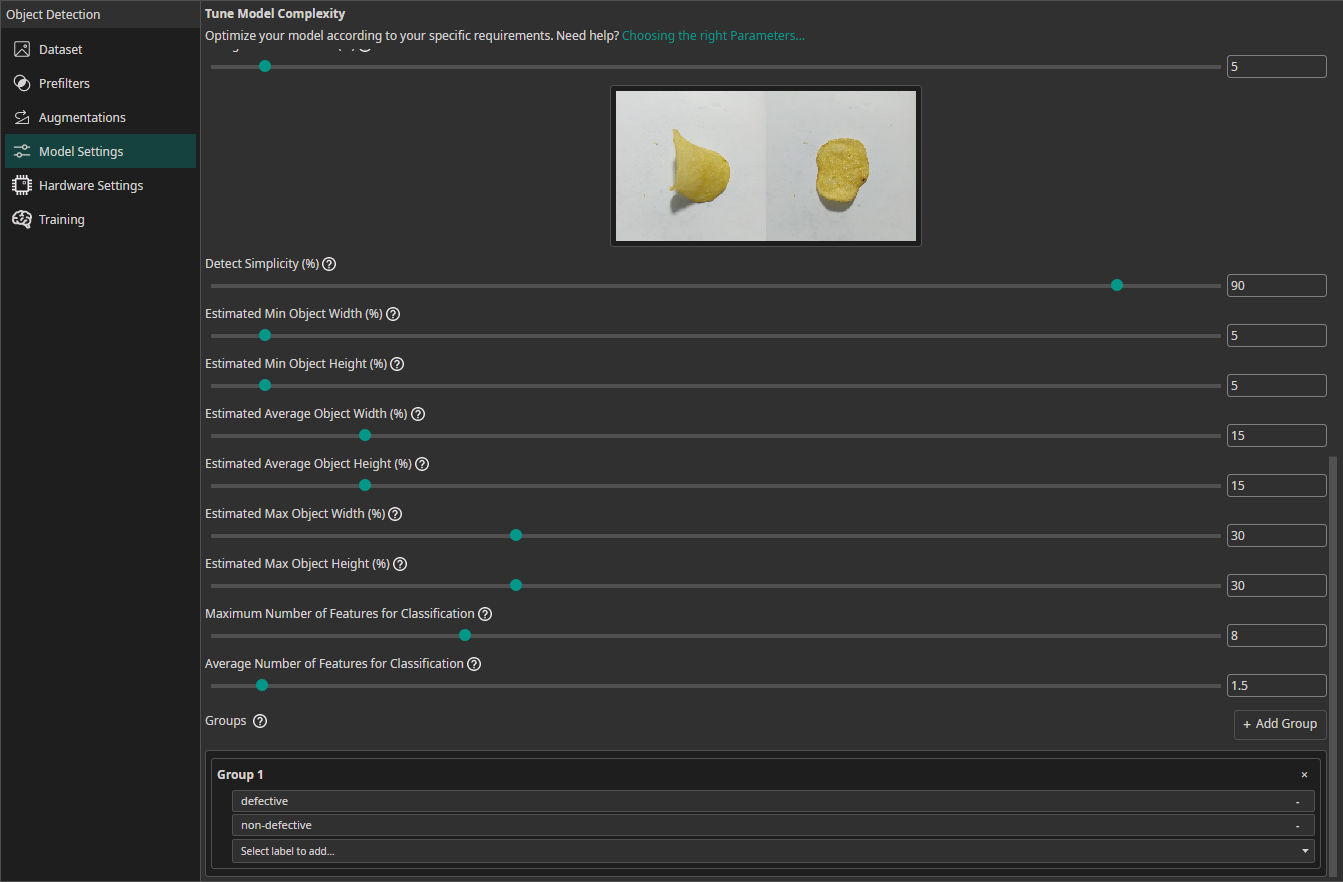
Estimated Min Object Width (%): Estimate the width of the smallest area that the model needs to analyze to make the correct decision.Estimated Min Object Height (%): Estimate the height of the smallest area relevant for the classification.Estimated Average Object Width (%): Estimate the width of the average area relevant for the classification.Estimated Average Object Height (%): Estimate the height of the average area relevant for the classification.Estimated Max Object Width (%): Estimate the width of the largest area relevant for the classification.Estimated Max Object Height (%): Estimate the height of the largest area relevant for the classification.Maximum Number of Features for Classification: This setting describes the maximum number of image features that may be relevant for a classification task.Average Number of Features for Classification: The average number of relevant features used for the classification.Groups(also available for object detection tasks): This setting is intended for advanced users. We recommend leaving all classes in one group unless you know what you are doing. By splitting the classes into multiple groups, you can divide your task onto multiple sub-models. ONE AI will generate an individual sub-model for each group that only predicts the classes that belong to that group. The sub-models are then joined to create a single unified model. This approach is practical if you have objects with significantly different sizes, e.g. long scratches and small nicks. By dividing the task onto sub-models, one model can focus on the large defects while the other focuses on the tiny defects.

Need Help? We're Here for You!
Christopher from our development team is ready to help with any questions about ONE AI usage, troubleshooting, or optimization. Don't hesitate to reach out!